
티스토리 뷰
[한빛아카데미] 운영체제 책으로 학습한 내용을 정리한 것입니다.
* 디스크의 구조
- 보조기억장치로는 자기디스크를 사용하게 되었으며, 자기디스크는 컴퓨터 시스템에서 대용량 보조기억장치뿐만 아니라 온라인 기억장치로도 사용함
(참고) 보조기억장치의 목적 : 방대한 데이터를 영구히 저장하는 것
- 디스크 시스템은 디스크 드라이버, 프로세서, 디스크 제어기로 나눌 수 있음
1) 디스크 드라이버 : 구동 모터, 액세스 암 이동장치, 입출력 헤드 부분의 기계적인 부분 담당하며, 탐색/기록/판독 등 명령 수행
2) 프로세서 : 원하는 컴퓨터의 논리적인 상호작용, 즉 원하는 데이터의 위치(디스크 주소)와 버퍼, 판독, 기록 등을 관리
3) 디스크 제어기 : 디스크 드라이버의 인터페이스 역할로, 프로세서에서 명령을 받아 디스크 드라이버를 동작함
[디스크의 종류와 구조]
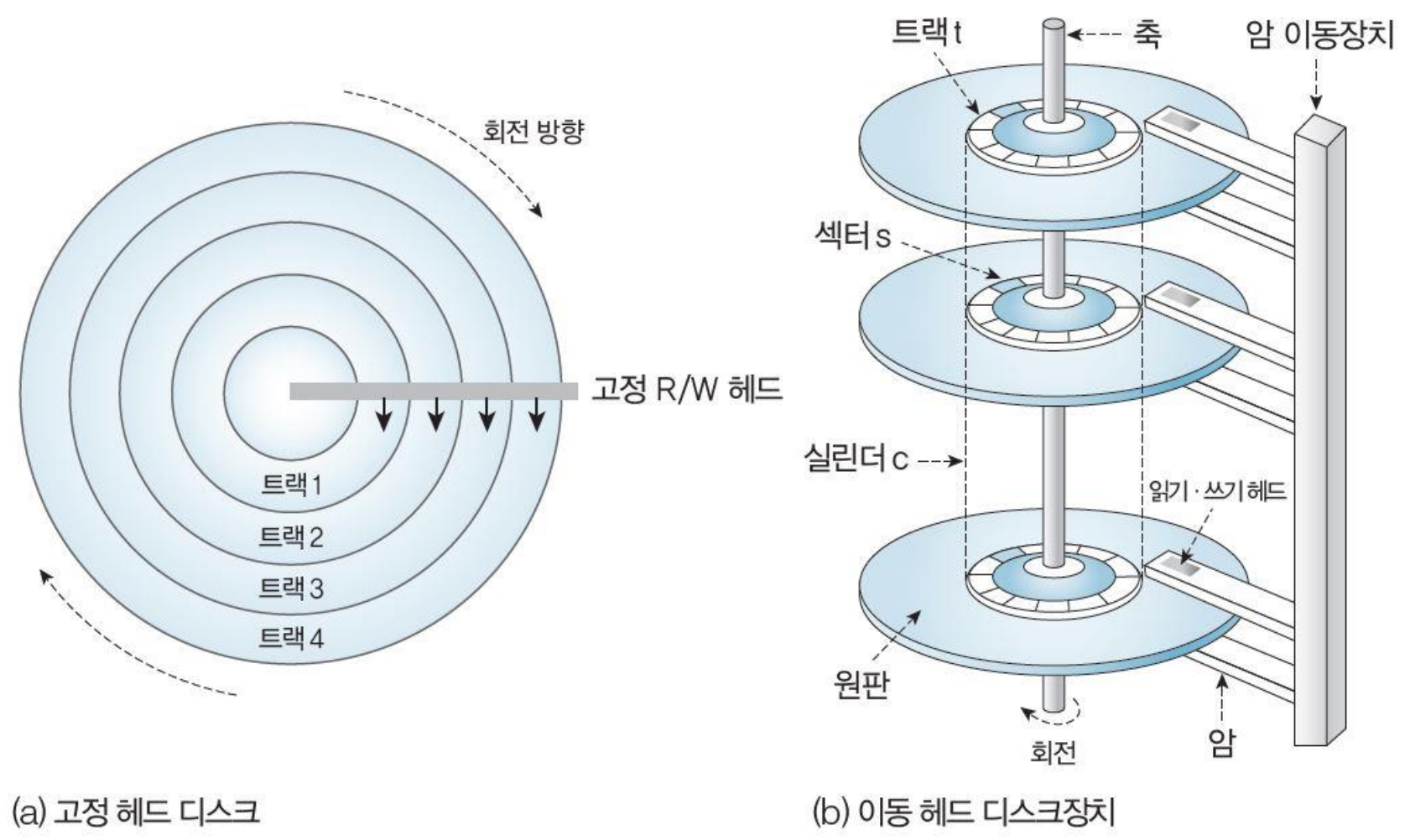
- 트랙(Track) : 원형 평판 표면에 데이터를 저장할 수 있는 동심원을 가리키며, 자기장의 간섭을 줄이거나 헤드를 정렬하려고 트랙 사이에 일정한 공간을 두어 트랙을 구분함
- 실린더(Cylinder) : 동일한 동심원으로 구성된 모든 트랙, 즉 동일한 위치에 있는 모든 트랙의 집합을 의미하며, 헤드의 움직임 없이 액세스할 수 있는 드라이브의 모든 트랙에 해당됨
- 섹터(Sector) : 트랙을 부채꼴 모양으로 나눈 조각을 의미하며, 데이터 기록이나 전송의 기본 단위로 일반적으로 512Byt의 데이터 영역으로 구성됨 / 고유 번호가 있어 디스크에 저장된 데이터의 위치를 식별할 수 있음
* 디스크 액세스 시간
- 회전하는 디스크의 섹터를 액세스 할 수 있는 시간
- 탐색 : 시스템은 헤드를 해당 트랙이나 실린더에 위치시켜 디스크의 원하는 섹터에 액세스
- 탐색 시간 : 탐색하는데 걸리는 시간
- 회전 지연시간 : 헤드가 지정된 트랙에 위치했더라도 원하는 섹터가 입출력 헤드 아래로 회전할 때까지 기다려야 함
- 전송 시간 : 디스크와 메인 메모리 간의 섹터를 주고받는데 걸리는 시간
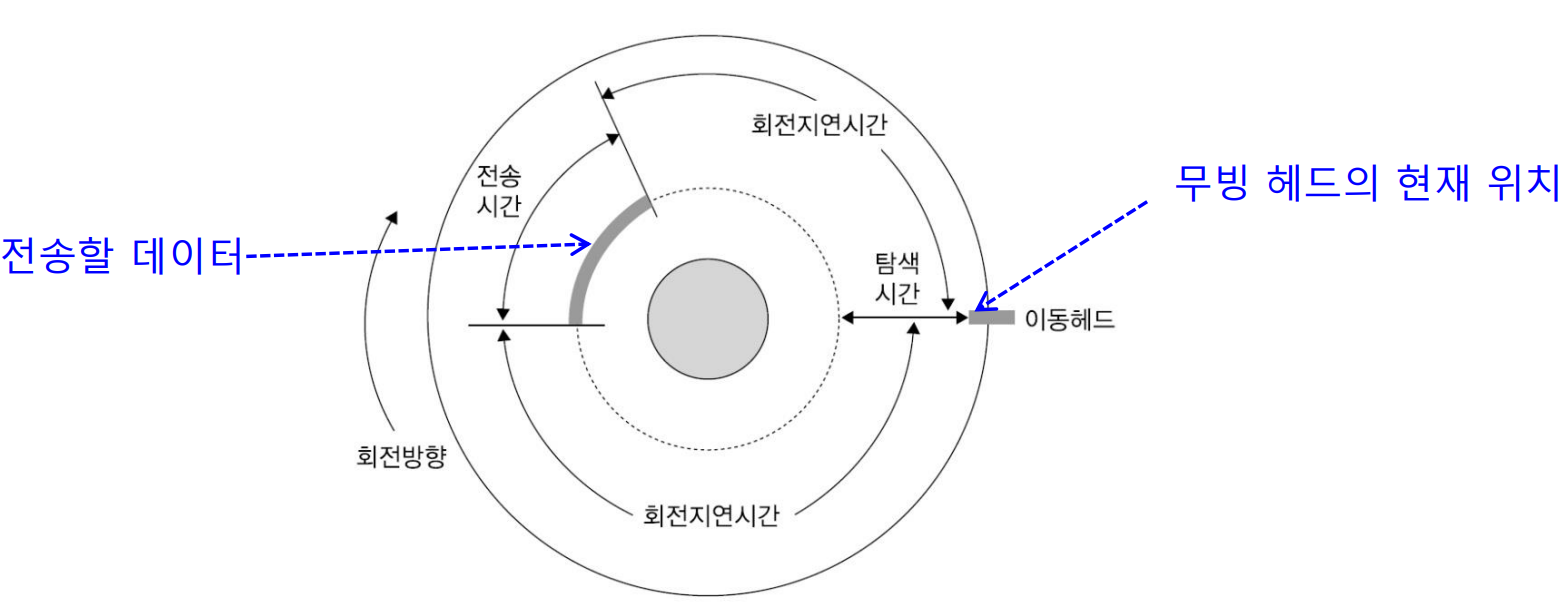
- 이동 디스크의 데이터 액세스 시간 = 탐색 시간 + 회전 지연시간 + 전송 시간
- 고정 디스크의 데이터 액세스 시간 = 회전 지연시간 + 전송 시간
* 디스크 스케줄링
- 디스크 스케줄링을 통해 요청을 도착한 순서대로 처리하지 않고, 재정렬함으로써 탐색 시간 최적화, 회전 지연 시간 최적화 및 처리량 향상을 기대할 수 있음
- 스케줄링 평가 기준
1) 처리량 : 시간당 처리한 서비스 요청 수
2) 탐색 시간 : 디스크 헤드(암) 이동 시간
3) 평균 반응 시간 : 요청 후 서비스할 때까지 대기시간
4) 반응(응답)시간 변화 : 반응시간 예측 정도, 즉 적절한 시간 안에 서비스하여 요청이 무기한 연기되지 않도록 방지함
- 디스크 스케줄링은 탐색 시간 최적화와 회전 지연시간 최적화로 분류할 수 있음
* 선입선처리(FCFS, First Come First Served) 스케줄링
- 요청이 도착한 순서에 따라 처리하는 스케줄링
- 프로그래밍하기 쉽고, 어떤 요청도 무기한 연기하지 않고, 본질적으로 공평성을 유지함
- 디스크 요청이 흩어질 때는 실행 시간 오버헤드가 적으며, 서비스 지연을 감소시키는 요청을 재정렬하지 않아서 일반적인 임의의 탐색 패턴 결과로 탐색 시간이 증가하면서 처리량이 감소한다는 단점 존재

* 최소 탐색 시간 우선(SSTF, Shortest Seek Time First) 스케줄링
- 디스크 요청을 처리하려고 헤드가 먼 곳까지 이동하기 전에 현재 헤드 위치에 가까운 모든 요구를 먼저 처리하는 방법
- 최소작업을 우선 수행하므로 디스크 요구의 기아 상태가 발생할 수 있음
- 공정성을 보장할 수 없고, 서비스를 무기한 연기할 수 있으며 응답시간의 높은 분산은 대화형 시스템에서는 받아들일 수 없는 단점

* 스캔(SCAN) 스케줄링
- 헤드가 디스크의 한쪽 끝과 다른 끝 사이를 계속해 왕복하면서 한 방향으로만 서비스하고, 디스크 가장자리에 도달하거나 트랙 0에 도달할 때까지 그 방향의 마지막 트랙까지 서비스한 후 그 역방향으로 전환
- 밀도가 높은 쪽의 요청은 상당히 오랜 시간 기다려야 함 -> 대기 시간이 균등하지 않음

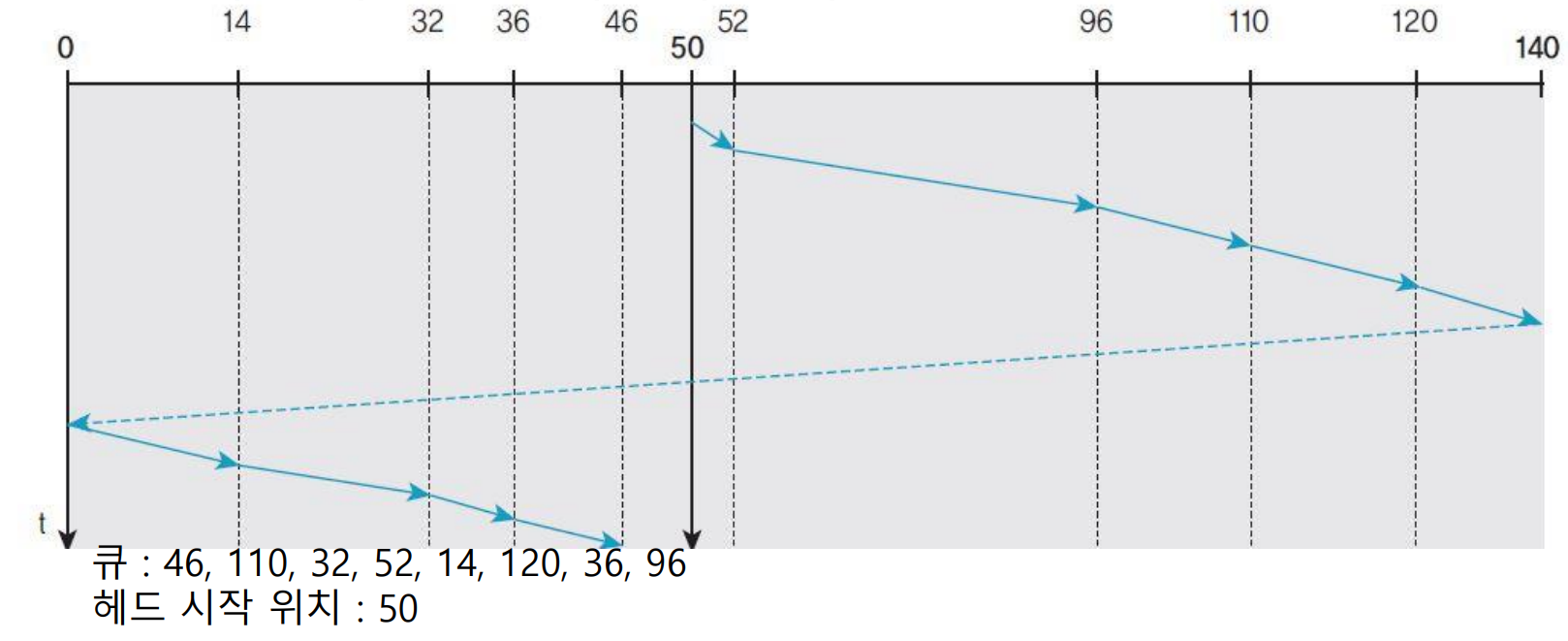
* 순환 스캔(C-SCAN, Circular-SCAN) 스케줄링
- 스캔 스케줄링을 변형하여 대기시간을 좀 더 균등하게 처리하는 방법
- 한쪽 끝에 다다르면 역방향 헤드로 이동하는 것이 아닌 다시 처음부터 요청을 처리함
- 동일한 실린더(트랙) 요청이 연속적으로 발생하면 무기한 연기될 수 있음
* F-SCAN 스케줄링 / N-STEP 스케줄링
- 스캔 스케줄링을 변형하여, 요청이 무기한 연기 되는 경우를 방지함
- F-SCAN 스케줄링 : SCAN 방식으로 특정 방향을 훑을 때, 대기 중인 요청들만 처리
- N-STEP 스케줄링 : SCAN 방식으로 큐에서 처음 N개의 요청을 처리하며 한 방향으로 훑는 과정을 완료하면 다음 N개의 요청 처리
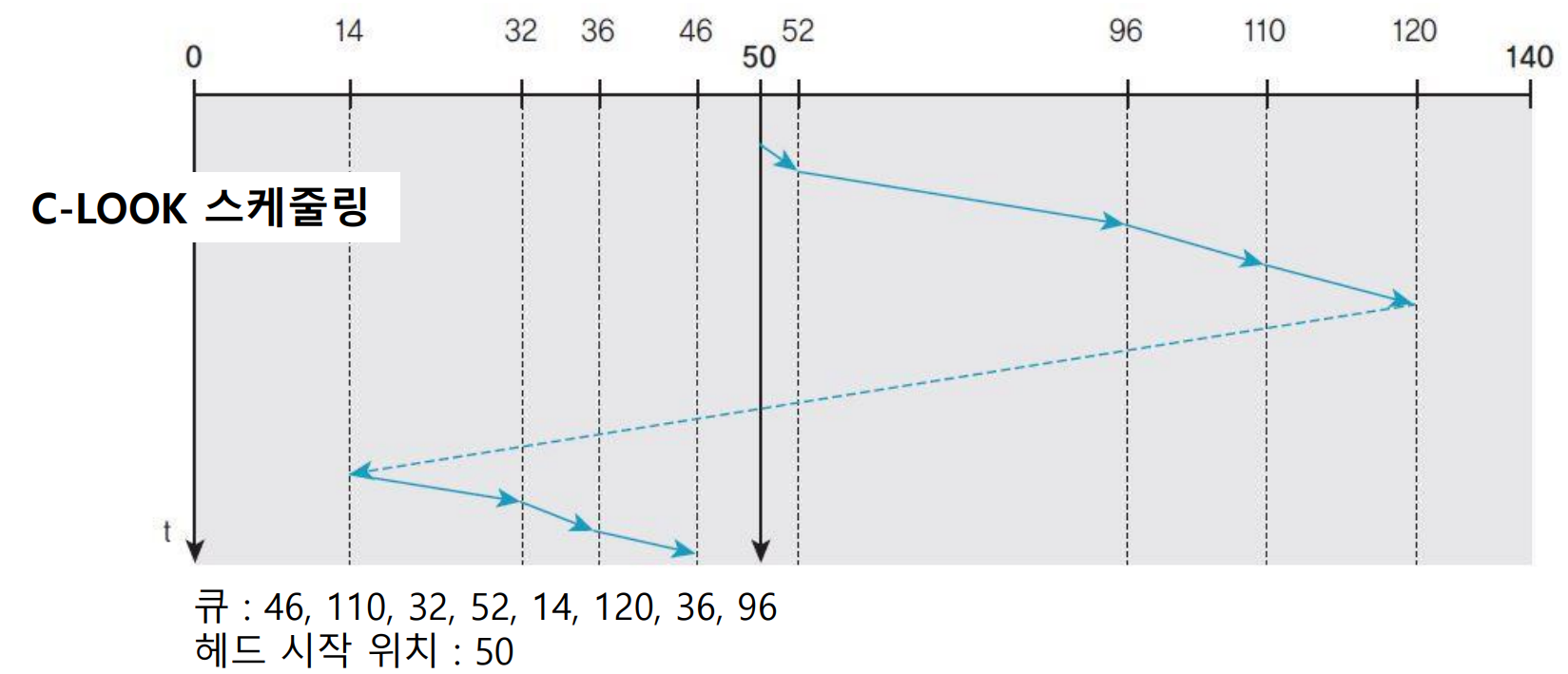
* 룩(LOOK/C-LOOK) 스케줄링
- 헤드를 각 방향으로 요청에 따르는 거리만큼만 이동하는 원리
- 현재 방향에서 더는 요청이 없다면 헤드의 이동 방향을 바꾸는 방법
* 최소 지연시간 우선(SLTF, Shortest Latency Time First) 스케줄링
- 모든 요청 중 회전 지연시간이 가장 짧은 요청을 먼저 처리함
- 트랙을 일정한 수의 블록으로 나눈 섹터를 토대로 요청들을 섹터 위치에 따라 큐에 넣은 후 가장 ㄱ가까운 섹터 요청을 먼저 처리함
- 고정 헤드에서는 탐색을 하지 않아 탐색 시간이 없음
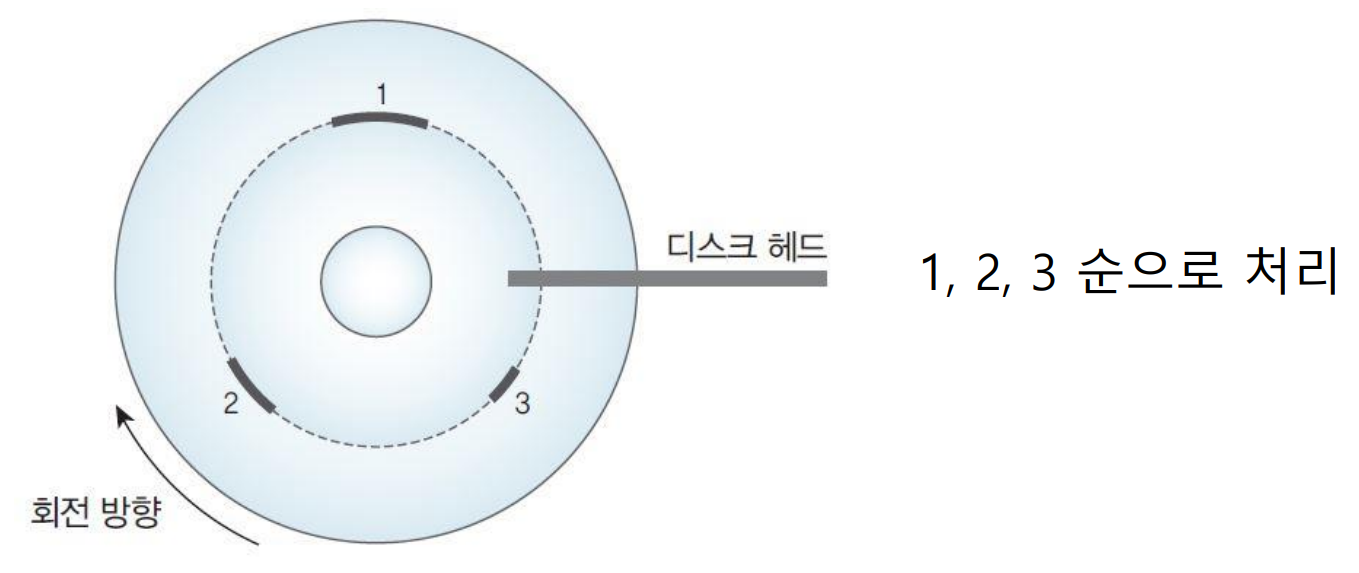
* 최소 위치 결정 시간 우선(SPTF, Shortest Positioning Time First) 스케줄링
- 가장 짧은 위치 결정 시간, 즉 탐색 시간과 회전 지연시간의 합이 가장 짧은 요청을 다음 서비스 대상으로 선택함
- 처리량이 많고 평균 반응시간은 짧으며, 가장 안쪽과 바깥쪽 실린더 요청이 무기한 연기될 가능성 존재
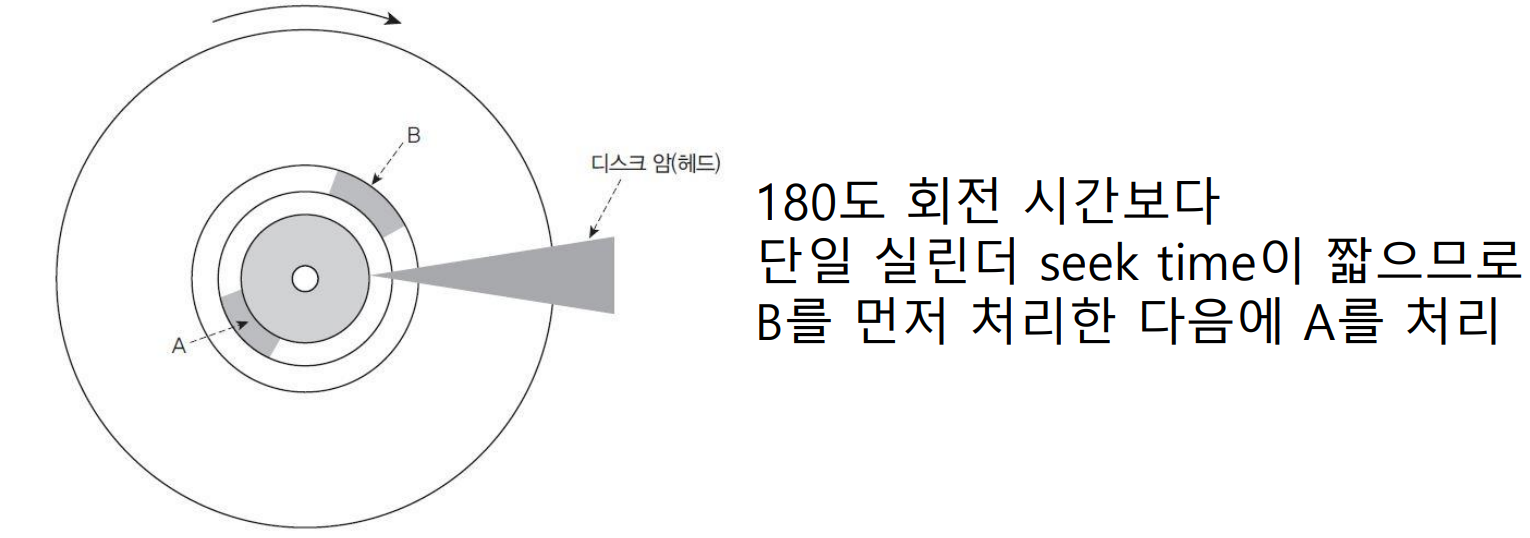
* 에센바흐 방법(Eschenbach Scheme)
- 헤드는 순환 스캔 스케줄링처럼 진행하지만 요청과 관계없이 트랙이 한바퀴 회전할 동안 요청을 처리하도록 재배열하는 알고리즘
- 1회전 동안 섹터의 많은 레코드를 처리하여 회전 지연시간을 줄일 수 있음
* RAID(Redundant Array of Inexpensive/Independent Dists)
- 운영체제로, 여러 대의 물리적 디스크를 하나의 논리적 디스크로 인식하는 기술
- 하드디스크 여러 개를 논리적 가상 디스크 하나로 구성하여 대용량 저장장치로 사용할 수 있는 방법
- 데이터를 하드디스크 여러 개에 분할/저장하여 전송속도를 향상시키며, 시스템 가동 중 생길 수 있는 디스크 오류를 시스템을 정지하지 않고도 교체 가능하다는 특징을 가짐
- 현재 RAID 0, RAID 1, RAID 0+1, RAID 5를 제외한 나머지 방법은 거의 사용하지 않음
* RAID 0 (스트라이핑)
- 일련의 데이터를 논리적 디스크 배열 하나에 일정한 크기로 나눠서 분산 저장하는 방법
- 대기 중인 다수의 입출력 요구를 병렬적으로 처리해 높은 전송률을 유지할 수 있음
- 스트립(Strip) : 크기가 일정한 섹터 또는 물리적 블록 단위
- 스트라이프(Stripe) : 스트립 하나와 각 배열의 구성 요소가 대응하는 논리적으로 연속적인 스트립의 집합
- 스트라이프가 있지만 데이터를 중복해서 기록하지 않아 장애 발생에 대비한 여분의 저장공간 없음
-> 안정성을 추구하는 RAID 시스템에 부합하지 않음
- 데이터를 입출력할 때 RAID컨트롤러에서 디스크 여러 개로 나눠서 쓰고 읽어 들임
-> 중요하지 않은 데이터에서 빠른 데이터 입출력 성능을 요구하는 동영상 편집 등에 적합함

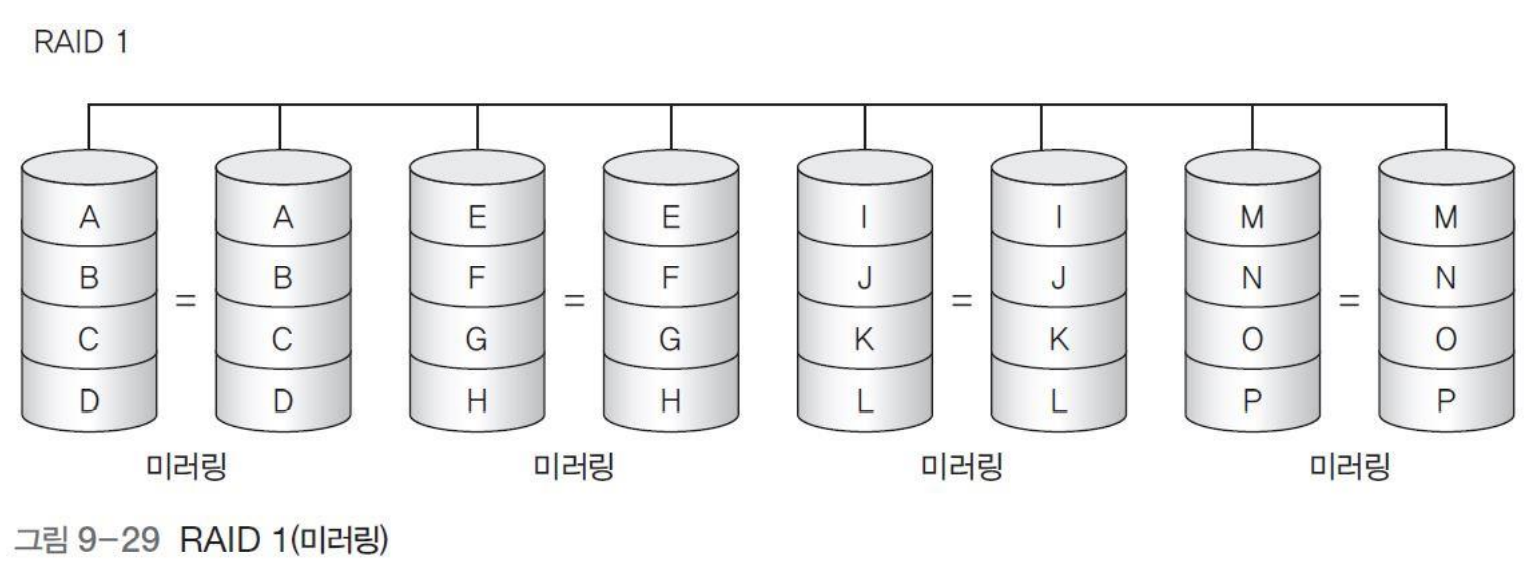
* RAID 1(미러링)
- RAID 0처럼 데이터 스트라이핑을 사용하면서 배열 내의 모든 디스크에 동일한 데이터가 있는 미러 디스크(Mirror Disk)를 가짐
- 논리적 스트립은 별도의 디스크 2개에 대응하는데, 미러링(Mirroring)이라고도 함
- 드라이브에 장애가 발생하거나 데이터에 손실이 발생해도 즉시 두번째 디스크로 액세스할 수 있음
- 전체 용량의 절반을 여분의 데이터를 기록하는데 사용하기 때문에 지원하는 논리적 디스크 공간의 두 배가 필요하여 비용 증가
- 시스템 드라이브와 같은 중요한 파일에 적합함
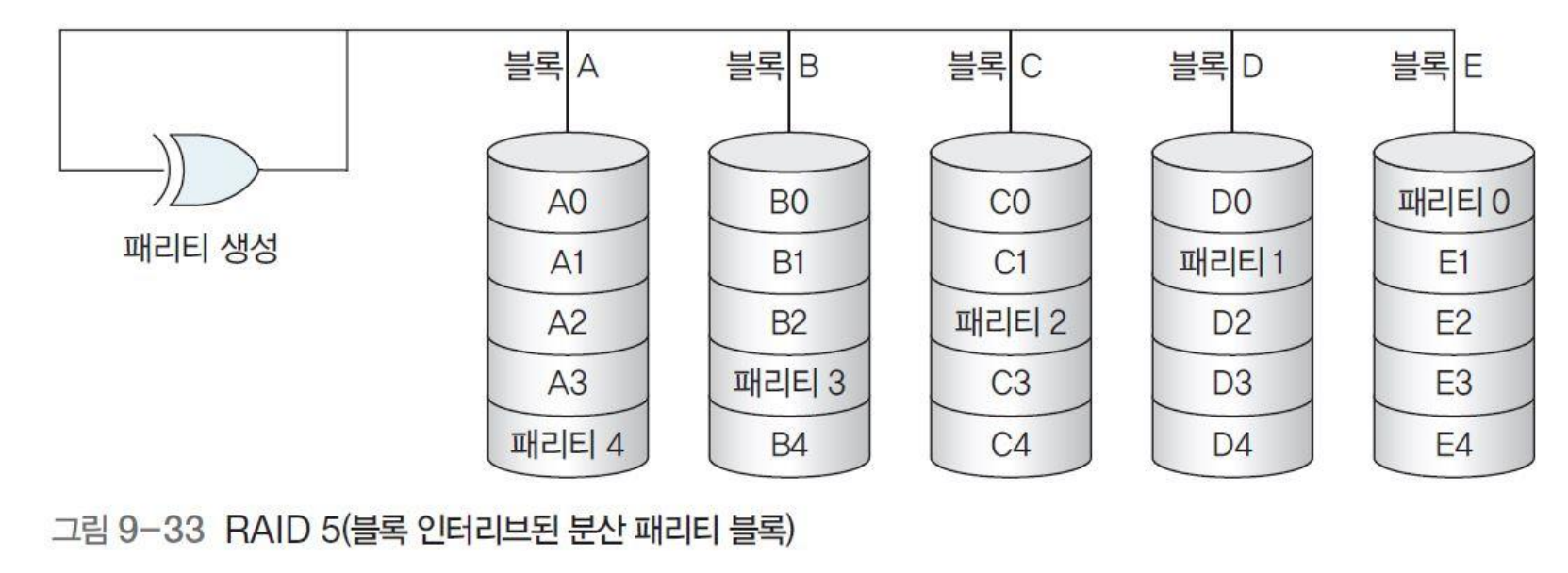
* RAID 5(블록 인터리브된 분산 패리티 블록)
- 데이터를 여러 디스크에 분산 저장하되, 오류 탐지를 위한 패리티(Parity) 정보를 모든 디스크에 나눠 저장하는 방법
- 패리티 정보를 나눠서 저장하기 때문에 패리티를 담당하는 디스크의 병목 현상을 일으키지 않음
- 병렬 입출력이 가능하기 때문에 기록과 읽기가 동시에 가능하며, 데이터 입출력 성능이 아주 빠르면서도 안전성 또한 높은 편으로 파일 서버 등 입출력이 빈번한 업무에 적합함
- 현재 가장 널리 사용하는 RAID방법
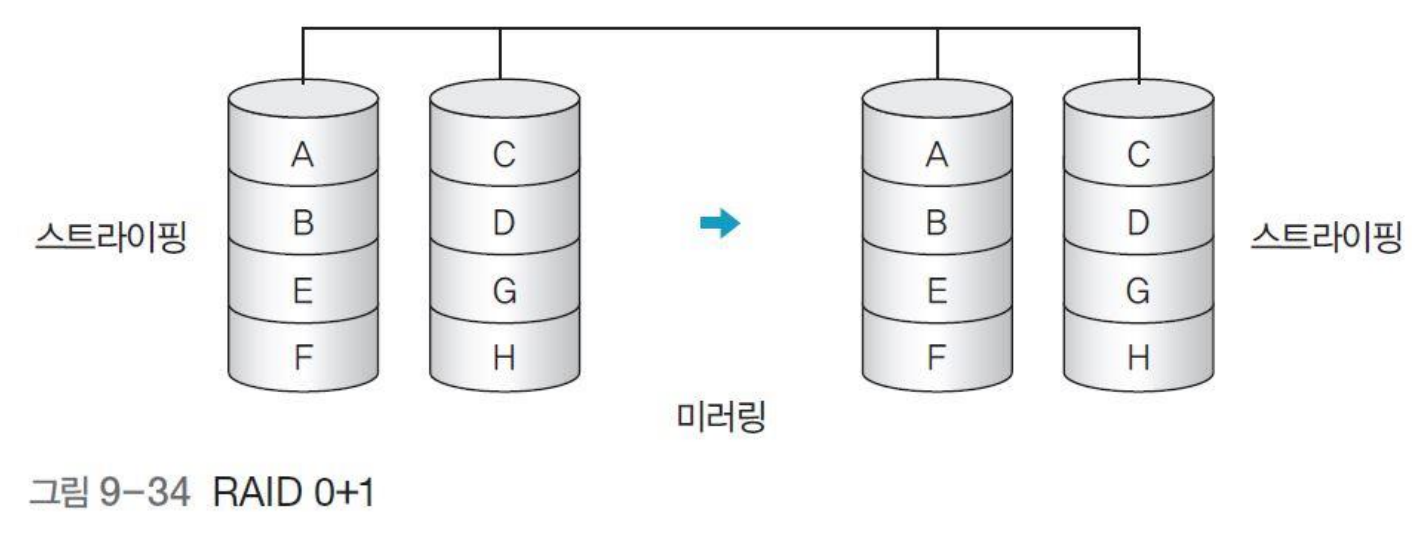
* RAID 0+1
- 스트라이핑 방법과 미러링 방법을 혼합한 형태로 각각의 장점을 살린 시스템
(참고) RAID 0(스트라이핑) 방법의 장점 : 빠른 속도, RAID 1(미러링) 방법의 장점 : 안정적인 복구 기능
- 미러링은 반드시 디스크 수가 똑같아야 하기 때문에 디스크 2개를 사용하여 스트라이핑하려면 최소 디스크가 4개 필요함
- 하드디스크 4개로 구성된 RAID시스템에서 디스크 4개에서 나눠서 읽어오기 때문에 읽기 속도는 빠르며, 미러링으로 동일한 디스크 복사본을 가지고 있어 디스크에 오류가 발생하면 복구 가능함
- 디스크가 여럿 필요하기 때문에 안정성과 빠른 속도가 모두 필요한 중대형 서버에서 많이 사용함
'개인공부 > 운영체제' 카테고리의 다른 글
| [운영체제] 입출력 시스템 (0) | 2023.12.02 |
|---|---|
| [운영체제] 가상 메모리(Virtual Memory) (0) | 2023.12.01 |
| [운영체제] 메모리 할당 방법 (0) | 2023.12.01 |
| [운영체제] 메모리 관리 (0) | 2023.11.30 |
| [운영체제] 스케줄링 알고리즘 (0) | 2023.11.29 |